No bullshit advice for cloud cost optimization
In this post, we will talk about cost optimization in cloud environments, and how to think and reason about your cloud bill. we will look into how and why cloud costs can get out of hands easily, and how to deal with it.
Intro
There are a lot of blog posts out there with a list of best practices, tips, and tools that can help you save on the cloud bill, they are great but they give you tips and tricks. I was looking for something that explains and teaches me how to think about cost in the cloud, I was looking for “Cloud Economics - 101”.
When I couldn’t find any relevant ones, I asked twitter hive-mind if anyone is interested in it, and wrote it.
In this post, I will focus more on how we should re-think our applications and architectures with the cloud in mind.
Cloud Native is often misunderstood as sticking code in a docker container and running it on Kubernetes. it is not “Cloud Native”, that’s how you end up with a big cloud bill.
We are spoiled by cloud, and often don’t think about how our code will run, and how much CPU, Memory, and Network will be used.
When we can scale things with a single API call, first thing that comes in our mind is to throw more resources at it (note: in some cases, it might be the right thing to do)
It’s great when we don’t have to think about resources used by code we write, but when we skip these questions during design phase, we are forced to think about them later when we are hit by a big bill. That’s when cost optimization comes into the picture.
I may sound like someone who hates cloud, but that’s not the case. We surely don’t want to go back to before the cloud era, but we should be aware of the cost and limits of the cloud
All aside, let’s see what we can do with that bill
Basics of Cloud Economics
Let’s learn some basics of cloud, and things to keep in mind when we are running on cloud
We are renting resources, not buying them
We are paying for resources per hour, so how long we use something plays a big role, we are billed per hour or second. Seems obvious but we tend to forget this
Data transfers are expensive
Moving data around is expensive, and depending on how far we move it, cost grows exponentially.
Moving data across VMs in the same data center(zone) will cost less, moving it across zones in the same region will be more expensive, and moving data across regions will be even more expensive Also, please don’t store backups in same zone/region to save money, it’s not advisable for obvious reasons.
Here, I am using GCP’s definition of the zone, and region, see 1
Low Hanging Fruits
Now that we discussed basic, let’s talk about how to pluck those low hanging fruits
Audit, Audit, and Audit
- Audit bills time to time, set weekly/monthly emails with billing summary to avoid surprises
- set billing alerts to get notified when bill grows
- It helps you avoid vendor-specific gotchas, like how GCP charges extra for unused static IPs
note: GCP has custom machine types, as per docs it can save up to 40% in cost.
Monitor And Breakdown Resource Usage
- We can not improve something if we can not measure it.
- Export detailed billing data, breakdown cost by SKU, and see what are the things that we are paying for. For example, Google Cloud Service has multiple cost components( SKU), like network, cross-continent network, etc. The same is true for other services as well. We saved money on GCS by doing this
Delete old things
- periodically audit and cleanup stopped VMs and disks that were created for testing something.
- delete old container images, build files and other things that you don’t need anymore
- Set a life-cycle policy on object stores (GCS/S3) to delete old things
Usage Discounts
Talk to your account manager, learn more about usage discounts. Almost every cloud provider has usage discounts, learn about it, run the numbers to see if you can save some money there. Google calls it committed usage discount
There are tools that help you with this, look for tools that work for your cloud provider. I have linked some at the end of this post
Designing for Cloud
Low hanging fruits are, well low hanging fruits, to gain long term benefits we will have to design our systems with cloud in mind. all the cool kids are calling it Cloud Native Architecture
Cloud Native Architecture is an overused term and everyone has a different definition of it. in this post, it means “building software that can exploit capabilities of the cloud, and deliver better service at lower operational cost”
Like everything in computing, the cloud has some trade-offs which we should be aware of. running on the cloud gives us the ability to provision infra with a single API call, but also makes us ignorant of cost.
Did you Know: we can burn 801 Million Euro in single API call on Azure 🤯
So far we learned basics, and how to dig deep into the bill and capture low hanging fruits. There are tools that can help you with but they are limited.
A tool will never be able to tell us how to architecture our system to save money, It will never tell us to index our db, drop extra fields from request, moving compute closer to data. Tools can monitor, we have look at that data and ask questions.
Tools will catch the obvious low hanging fruits but big gains will come when you look at your architecture and ask some questions, like “Why are we doing this?”
We need to approach this as a resource optimization problem and not as a cost problem. after all, we paying more because we are using more resources, so it’s as easy as using less, or optimize existing systems to get more use out of them.
Ask “Do we need that?” bunch of times
Kafka is under load, Ask?
- We are moving around lots of data in Kafka?
- Look at what are we moving around before adding a new node in the cluster
- Can we drop some fields to save disk and network cost?
- Can we tune it to get more use out of it
PostgreSQL is under load, Ask?
- What are we querying?
- Look at slow queries, index items that are queried often
- See if you are selecting data that you don’t need (selecting all columns when you only wanted name)
- See if you can batch writes, or read
- See if you can redirect read traffic to replica (maybe that analytics batch jobs is fine with stale data)
As you can see, for each system these questions will vary but the gist of the story is that stop doing unnecessary work, and understand the system you are using to get more use out of them.
In almost all cases, big parts of the bill are for CPU, Memory, Network, and Disk. If we can reduce these, the bill will come down.
Build or turn existing workload into stateless workloads, push state down the line. design things that can be killed and spawned back any moment, and run them on preemptable/spot VMs to save money
Few guidelines that are applicable for most systems
-
Reduce load on systems
- cache, cache, and cache: add multiple layers of cache if your data doesn’t change often
- profile slow queries
- do only what you need
-
Get rid of spiky workload
- consolidate your workload to get better usage out of your system
- put a buffer in front, and use batch write/reads, etc to turn it into uniform
- A sustained and predictable workload is better in cloud
-
Put resource constraints when you design
- have a memory, CPU, and latency budget (e.g.: service should handle 1000 requests per seconds with p99 of 10ms, on 1GB, and 1 CPU resources)
-
Small things add up at scale
- for 1 million requests, 100kb extra data per request be 100 GB
Does this work?
Yes, we got more then 25% reduction in bill by plucking some low hanging fruits, and doing architecture changes.
Architecture changes have given us massive gains but they were long term efforts, I talked about one at Large Scale Production Engineering (LSPE-IN) meetup, see slides for details
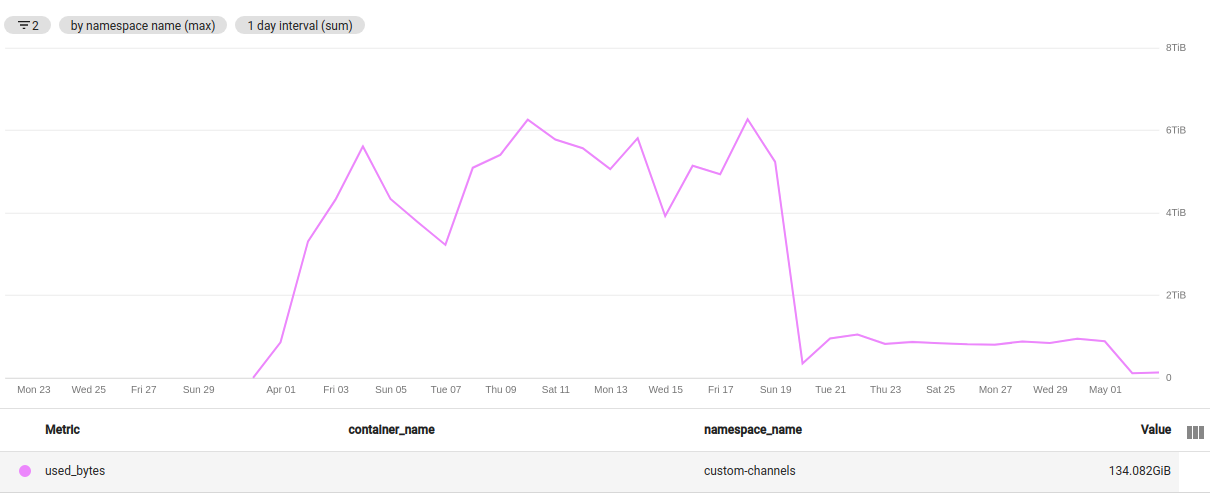
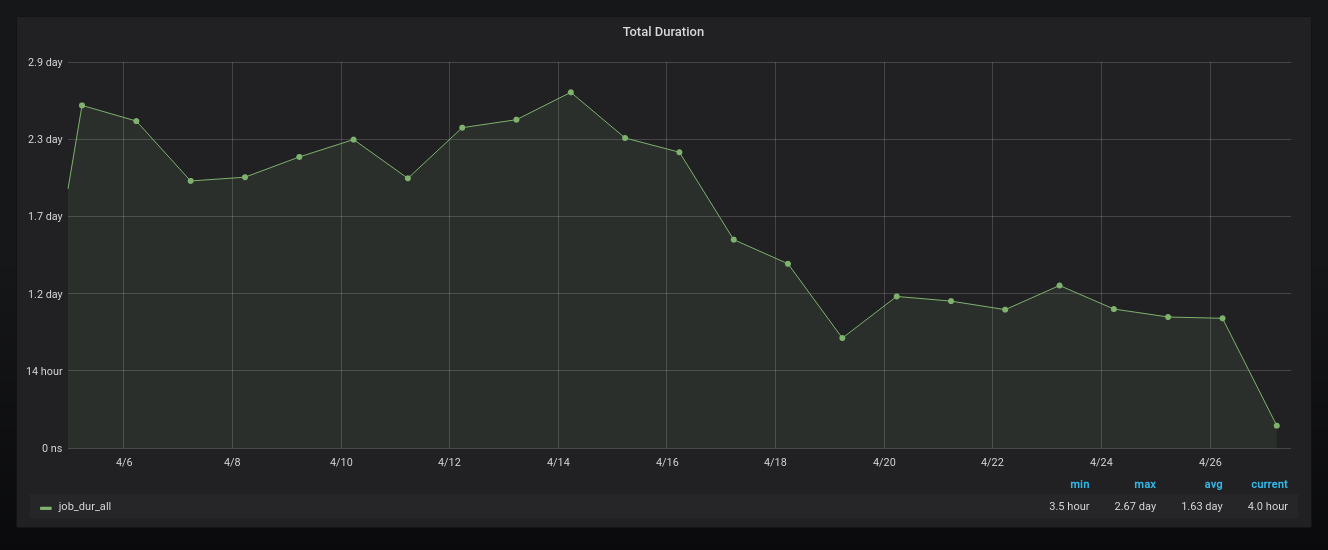
Here are few graphs to highlight gains, memory and processing time is going down as we are rolling out new service
Memory usage
Processing Time
FAQ
“But I have credits??”
Cloud credits are like the first free hit from your drug dealer. Cloud is a big moneymaker, AWS generated revenues of 35.03 billion U.S. dollars in 2019
They can very easily afford that first free hit, these credits are customer acquisition cost, you will pay for it eventually
“But my cloud provider recommends this setup”
Sure, but don’t blindly follow what they say. Ask why? and do cost-benefit analysis, reason about it, and see if it’s the best setup for you.
“This new thing is best, everyone is doing it, let’s do it”
This is what I call a hype train before you board that hype train, put some thought on why you should use it.
Your customers don’t care if their request was served by a monolith, or 100 micro-services running on Kubernetes, they want a good experience when they are using your product.
Outsourced Advice
tweets/posts with advice on how to save on cloud bill
- We were paying big money for docker image pulls because our docker registry was in different continent then cluster
- We dropped our cloud costs by 61% in 2 hours by the novel strategy of looking at the bill and turning off things we weren’t using
- Cluster Management at Google with Borg by John Wilkes, not directly related to cloud cost optimization but a great watch
- Zombies eating your AWS bill?
Tools
Closing Note
Hopefully, it was helpful and helped you with cost optimization, tweet at me for corrections, and share your learning from cost optimization exercise.
If you are working on cost optimization, I would be happy to chat and compare notes
Especially, If you are a startup and looking to cut down cloud bill during these times, I am more then happy to help, please reach out
PS: I can officially call myself a cloud economist
Thanks @srijancse,@vindytalks,@vidusheeamoli and @shlok_15 for reading drafts.
footnotes:
-
A region is a specific geographical location where you can host your resources. Each region has one or more zones; most regions have three or more zones. For example, the
us-west1region denotes a region on the west coast of the United States that has three zones:us-west1-a,us-west1-b, andus-west1-c. ↩